
如果你修習過任何機器學習課程、或者讀過任何資料科學課本,ROC 曲線的定義與用法幾乎都是必考問題,我也不得不承認,ROC 曲線的 X 軸 Y 軸代表什麼、真陽性率(TPR)與偽陽性率(FPR)各自的算式定義、還有 AUC 曲線下面積的應用方式,我超級容易忘記!
為了準備求職的 機器學習面試,我終究必須牢記 ROC 曲線的各項細節,過程中我發現圖像化的方式更適合幫助我自己長期記憶。
因此,在這則筆記,我將分享 ROC 與 AUC 的大量圖解。本文將先說明 ROC 曲線幫我們在分類問題解決什麼痛點、TPR 與 FPR 的分子分母拆解記憶法、最後介紹如何用圖像連結 ROC 與 AUC 之間的關聯性。
我衷心相信你讀完這則文章的圖解後,將再也不會忘記 ROC 曲線、TPR、還有 FPR 的定義!
ROC 曲線:閾值與決策品質的權衡#
ROC 曲線是 Receiver Operating Characteristic Curve 的縮寫,此名稱來自於起源的 二戰軍事用途,ROC 曲線的功能是呈現分類器在不同閾值下的決策品質。
一般機器學習教科書提及 ROC 曲線都是直接從算式定義開始講解,一堆 TPR、FPR 等等術語,令人頭昏眼花。如果你跟我一樣,也是常常忘記算式與定義的類型,我認為只要優先搞懂以下這個分類模型的關鍵問題,就能深度理解 ROC 曲線、不會再忘記了:
分類模型只會輸出機率,不會真的幫你「分類」
在機器學習領域的分類問題,我們通常會把分析模型稱為分類器(Classifier),好像模型會幫我們做好分類一樣,但實際上不是如此!不論是 貝氏分類器、或者羅吉斯回歸,統計模型只負責輸出機率,最後要怎麼分類是決策者的職責。認清這點,就能理解 ROC 曲線的價值了。
氣象台播報的降雨機率是個很好的例子,氣象台不會幫你分類、不會把明天的天氣分成「會下雨」或者「不下雨」兩類,而僅會播報降雨機率是多少,我們作為此資料的使用者,要自己決定是否相信會下雨。如果你今天打算在咖啡廳坐一整天,就算降雨機率 60% 你可能也會懶得帶傘;如果你正打算曬衣服,光看到降雨機率 30% 你可能就會改變心意不曬了,要是下雨把衣服淋濕要重洗一遍很麻煩。
如以上降雨機率案例所述,對於不同資料使用場景,決策的閾值(Threshold 或者 Cut-off)—也就是機率門檻值—將會不同,ROC 曲線的核心目標正是要呈現不同閾值會對你的決策品質造成什麼影響。
(ROC 曲線分析是針對二分類問題衡量決策品質,以下文章講的「分類」都是指二分類問題)
ROC 曲線的 X 軸與 Y 軸圖像記憶術#
ROC 曲線的組成來自位於 X 軸與 Y 軸的兩大元素,他們是衡量決策品質的兩個關鍵數據:真陽性率(TPR)與偽陽性率(FPR),這正是我個人學習 ROC 曲線時最大的痛苦,我永遠會忘記這兩個數據的算法跟定義!經過我多年反覆複習之後,我覺得最好的記憶法是拆解分子與分母。
首先是分子,分別是真陽性與偽陽性的樣本數量,這兩個數據都是來自決策者對正樣本的預測結果:
- 真陽性(True Positive):決策者預測為正樣本,且真實答案確實是正樣本
- 我認為會下雨,而出門後確實遇到下雨
- 偽陽性(False Positive):決策者預測為正樣本,但真實答案是負樣本
- 我認為會下雨,但出門一整天都沒有下雨
- 「假警報」(False Alarm)
(補充:正負樣本是針對二分類問題的真實資料而言,正樣本的意思是真實答案為正向;例如真實資料顯示有下雨;反之為負樣本,例如資料顯示實際上沒有下雨)
值得注意的要點是,以上兩數據都是基於「決策者預測結果為正樣本」,筆者好豪建議可以這樣記憶:
我們作為決策者當然只在乎預測為正樣本的情形!
舉例而言,我們只在乎預測「會下雨」之後,實際上到底有沒有下雨,而預測「沒有下雨」的情形,相對沒有那麼重要。因此,ROC 曲線的分子只包含預測為正樣本的數量,再依據這些正樣本預測到底是否正確、分別放到 X 軸與 Y 軸數值的分子項。
再來是分母的元素,概念較簡單,分別是正樣本與負樣本的數量、也是各自放到 X 軸與 Y 軸數值的分母項。這兩個數據都是來自於真實答案、亦即來自於資料。
最後我們能把分子與分母綜合起來看:
- 真陽性率(True Positive Rate, TPR)= 真陽性數量 / 真實答案為正樣本數量
- 真實答案的正樣本又對應到分類決策的兩個元素:預測是正實際上也為正、預測是負但實際上為正
- 因此可以會寫出這個常見的公式:
TPR = TP / P = TP / (TP + FN) - 在特定領域,TPR 也被稱為 Sensitivity 或 Recall
- 偽陽性率(False Positive Rate, FPR)= 偽陽性數量 / 真實答案為負樣本數量
- 同樣地,真實答案的負樣本對應到分類決策是:預測是負實際上也為負、預測是正但實際上為負
- 公式:
FPR = FP / N = FP / (FP + TN) FPR = 1 - [Specificity](https://zh.wikipedia.org/zh-tw/%E9%9D%88%E6%95%8F%E5%BA%A6%E5%92%8C%E7%89%B9%E7%95%B0%E5%BA%A6)
我認為用分子與分母拆解的方式可以更牢靠地記憶 TPR 與 FPR 定義,主因是這種拆解很適合在腦海中圖像記憶 ROC 曲線的 X 軸與 Y 軸,就如下圖所示:

(製圖:好豪;參考圖片:sklearn)
如何解讀 ROC 曲線#
這則筆記前面強調過分類模型只會輸出機率,不會真的幫你分類,而分類的決策又取決於閾值(機率的門檻值),ROC 曲線的目標是要呈現不同閾值會造成什麼不同的決策品質。
我認為,學習並牢記怎麼解讀 ROC 曲線最好的方式就是學會怎麼畫。畫出 ROC 曲線的步驟如下:
- 把預測的機率值由大到小排列
- 對於每個預測的機率值,把它當作新的閾值,並計算出 TPR 與 FPR
- 步驟 2 算出的(多個) TPR 與 FPR 依序對應到 Y 座標與 X 座標,標示在圖上
第一步驟的機率值依大小排序是解讀 ROC 曲線的關鍵!排序後會更容易在腦海中想像出「高於閾值的預測為正樣本、低於閾值則預測為負樣本」的視覺化,以下圖示我們以 5 個資料點作為簡單的範例:
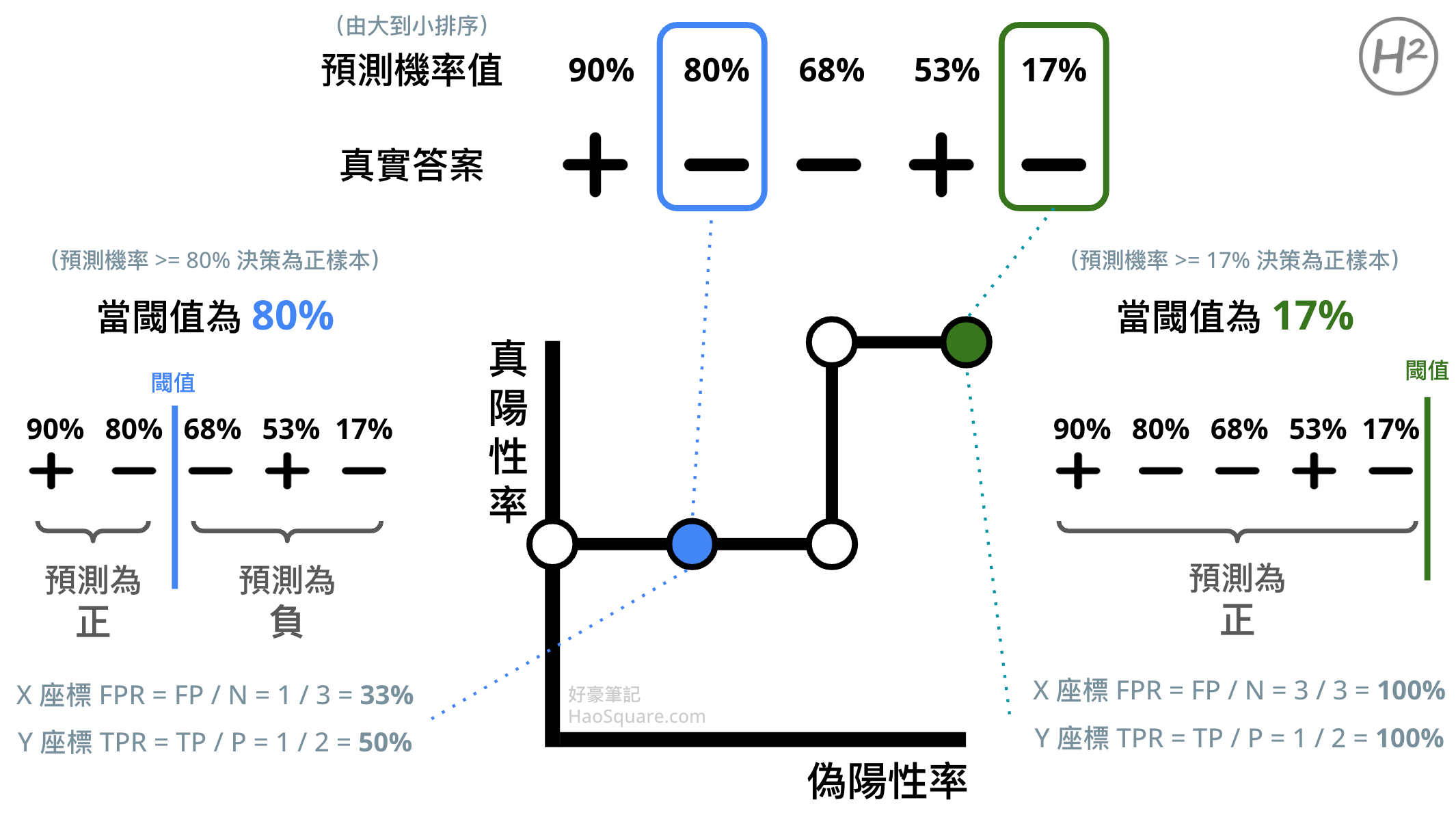
(以上這張 ROC 曲線畫起來像階梯形,只是因為本文為求簡化、使用的資料點只有 5 個。一般情況,資料點足夠多時,還是可以畫得出平滑的「曲線」的)
此外,我認為善用極端狀況的參考點也能夠幫助記憶 ROC 曲線的解讀方式,圖表上至少有 4 個參考點值得注意:
- 最左上角:X 軸
FPR = 0%,Y 軸TPR = 100%- 「完美分類」
- 所有的正負樣本都 100% 正確地分類
- 最左下角:X 軸
FPR = 0%,Y 軸TPR = 0%- 「超級保守」
- 全都分類為負樣本,完全不敢預測任何一個資料點為正樣本
- 也可想成:閾值無限大,模型輸出沒有機率會超過閾值
- 最右上角:X 軸
FPR = 100%,Y 軸TPR = 100%- 「極度寬鬆」
- 全都分類為正樣本,閾值形同虛設
- 也可想成:閾值無限小,模型輸出再小的機率都會超過閾值
- 最右下角:X 軸
FPR = 100%,Y 軸TPR = 0%- 「徹底相反」
- 超糟糕的分類決策,預測全都跟正確答案相反
同時,位於對角線(y = x)的每個點也都值得參考,對角線上的所有點都代表「完全隨機亂猜」,也就是說,不管分類器看到什麼樣本,都有 50% 機率預測為正樣本、也有 50% 機率預測為負樣本,非常公平地在兩個分類之間亂猜。

(這些參考點與 45 度角輔助線對我們選擇閾值超級重要,有興趣的話可以接著閱讀 這篇文章 了解如何圖像化找出 ROC 曲線上的最佳閾值)
AUC 曲線下面積:多個分類模型比較表現#
以上幾個小節,討論的都是僅在單一條 ROC 曲線比較不同閾值對成效影響的情境,我們在前面也學到,一條 ROC 曲線隨著不同閾值會有無限多個 TPR 與 FPR 數據來呈現決策品質,那想要比較多個分類器的決策表現時,該怎麼辦?
這個小節我們介紹一個更有效率的指標:AUC,用來同時評估多個分類器的表現。
AUC 是 ROC 曲線以下形成的面積(Area Under the Curve),AUC 越大表示分類器表現越好。我們可以想像,AUC 的功用是把模型表現從原本隨著不同閾值產生的無限多個 TPR 與 FPR「濃縮」成單一個面積數據。這麼做有兩大好處:
- 不受閾值限制:不用選特定閾值,AUC 會「摘要」所有閾值、用單一數字衡量整條 ROC 曲線的決策品質
- 適合多分類器比較:每一條 ROC 曲線的成效只濃縮成單一個數字,不同分類器經由 AUC 數值簡單地比大小就可以快速看出決策品質差異
為什麼 AUC 曲線下面積越大代表決策品質越好呢?筆者好豪個人偏好用基礎微積分學過的「黎曼和」來理解。
想像在 ROC 曲線上畫一條縱向的直線(請見下圖),這條直線每個點 FPR 都相同,而 FPR 又代表偽陽性、是一種錯誤率,在錯誤率相同的情況下,我們當然希望分類器的正確率—TPR—可以越高越好。換言之,在同一條縱向直線上,我們希望 TPR(Y 座標位置)越高越好。

在同一條縱向直線上越高、表示決策品質越好,接下來把這個特性進一步用長條圖來想像:在每個 FPR 數值(不同 X 座標)的不同長條都是越高越好。那麼,所有 FPR 形成的所有長條如果需要「濃縮」成一個數字,只需要把長條的所有高度相加就好,所有長條高度的加總正是這整個長條圖的面積。而黎曼和的意思即是:長條圖的每個長條寬度只要切得夠細、切出無限多個長條,將會逼近真正的 AUC 曲線下面積。

通常,AUC 要有多個分類器、多個 ROC 曲線之間比較才有意義。畢竟,只有一個 ROC 曲線的單一個 AUC 面積數字,無從知曉它究竟算是大還是小。跨分類器在多個 ROC 曲線比較決策品質表現的方式非常簡單:AUC 數值越大的分類器,分類決策品質(正確率)越高。
看過以上視覺化後,我們已經能用長條圖的方式直觀理解 AUC 越大代表分類決策品質越好,現在我們還能延續這個特點進一步想像:
ROC 曲線越靠近左上角,AUC 曲線下面積會越大
也就代表分類決策品質越好

用 AUC 來快速比較多個模型的分類表現,是不是好看又易懂呢?
實際上,AUC 除了在圖形上代表面積,其數據亦存在數學意義:AUC 代表隨機一個(答案為)正樣本被預測出的分數高於隨機一個(答案為)負樣本的機率。更囉唆地解釋:先隨機選一個已知答案為正的樣本,再隨機選一個已知答案為負的樣本,AUC 代表分類器預測此正樣本比此負樣本更可能為正樣本的機率。值得注意的是,AUC 的此數學意義同樣與閾值無關、不受閾值選擇限制喔!
以下這張 Google 機器學習教材 的視覺化解釋方式是另一種理解角度,AUC 代表隨機一個正樣本會比隨機一個負樣本被分類器排序更靠前的機率:

AUC 代表某隨機正樣本比某隨機負樣本排序更靠前的機率
(來源:Google 機器學習教材)
(補充:AUC 這個英文縮寫指的單純是曲線以下面積,但不一定是「ROC 曲線」的曲線下面積,也有可能是指其他曲線,例如 PR 曲線,所以有些研究者會更清楚的寫為 ROC-AUC 或 PR-AUC 以避免混淆。本文寫的 AUC 指的都是 ROC-AUC)
結語#
在這則機器學習評估分類問題的筆記,總結出以下兩個使用 ROC 曲線的重點:
- 一條 ROC 曲線:單一個分類器比較不同閾值的成效
- 多條 ROC 曲線:用 AUC 比較多個分類器整體表現
在同一條 ROC 曲線上,即使模型輸出的內容不變,設定不同閾值後,決策者會給出不同的正負樣本預測,因此也會產生不同的 TPR 與 FPR 成效。看到這裡,下一個關鍵問題會是:**究竟該在 ROC 曲線選哪個閾值才好?**我在下一篇文章將繼續探討這個問題,有個方法簡單到用眼睛就能一秒回答最佳閾值選擇!推薦你繼續閱讀:ROC 曲線上的最佳閾值選擇方法 Youden Index 介紹。
此外,一條 ROC 曲線實際上能設定無限多種閾值、給出無限多種 TPR 與 FPR 組合,我們可以用 AUC 曲線下面積來將決策品質總結成單一個數字的評估指標,AUC 這個指標很適合快速比較多個分類器的成效差異。
希望這則筆記與你分享圖像化的 ROC 與 AUC 解讀方法,能幫助你更深刻理解 ROC 曲線的意義,更重要是,期望幫助你牢牢記住 ROC、TPR、FPR 的定義,不再動不動就忘記!
參考資料:
- 《Kaggle 競賽攻頂秘笈》
- 維基百科:ROC Curve
- 《資料科學的建模基礎》第 14 章:評估模型的指標

如果這篇文章有幫助到你,歡迎追蹤好豪的 Facebook 粉絲專頁、Instagram 與 Threads 帳號,我會繼續分享數據分析與機器學習的知識;也可以點選下方按鈕,分享給熱愛資料科學的朋友們。