
從 ChatGPT 問世到 2024 年的現在,AI 彷彿要取代一切的焦慮感持續蔓延,資料科學領域也不例外,大家都想知道資料科學家的飯碗還能保住嗎?這則筆記將會以好豪的個人觀點出發,回答幾項每個數據愛好者都好奇的問題:
- 在 AI 風潮下,資料科學家或數據分析師的職涯,還適合長期發展嗎?
- 資料科學家的技能會被 ChatGPT 取代嗎?其他同事拿 AI 工具就能自己做分析、還需要我嗎?
- 如何創造自己身為資料科學家的獨特價值、並且避免 AI 取代的焦慮?
事實上,即使在這個 AI 無遠弗屆的時代,資料科學家仍是企業不可或缺的角色。本文將深入分析為什麼我認為資料科學家在業界仍有其地位、為你揭開資料科學家的核心競爭力、以及我們未來該用什麼方式發展數據職涯,希望這篇文章能帶給你更多樣的想法、協助你做出更明智的職涯選擇。
註記:
- 本文以產品分析類型的資料科學家、以及就業導向為核心,關鍵字會是 Product and Insights Analytics
- 如果你的志向是學術研究、或者更偏好資料工程(Data Engineer)與 AI 機器學習演算法(MLE)類型工作,請務必再多參考其他 AI 專家的意見
- 感謝 R 同學給此部落格 意見回饋,提供我寫作這篇文章的動機
有了 AI,還需要資料科學家嗎?#
自從 ChatGPT 橫空出世、還有了 一鍵完成數據分析 這種全自動化功能,大家都在問,有超強 AI 之後還需要資料科學家嗎?做這一行還有前途嗎?
發明 ChatGPT 的 OpenAI 公司直接回答我們了:資料科學家持續徵才中!
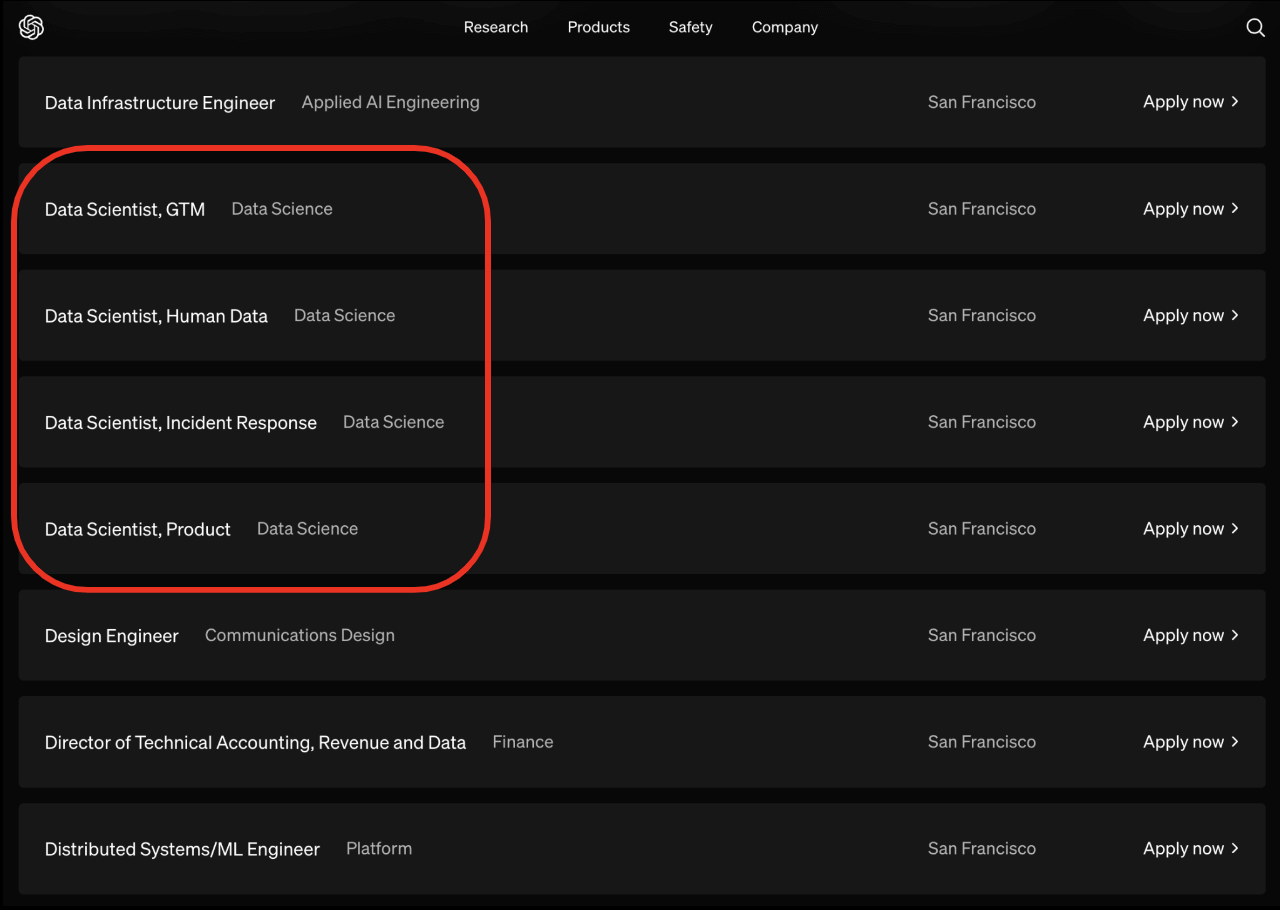
(圖片來源:OpenAI 公司網站,截圖於 2024 年 7 月)
資料科學還會不會是好的職涯,取決於企業(就業市場)是否看重這項職能,我相信在可見的未來,「人類」資料科學家和數據分析師的角色在企業仍然很重要,有以下四點理由。
首先,數據驅動決策(Data-Driven)是不變的趨勢,在商業和科學界更只會變得越來越普遍。各公司都在推出 AI 產品的同時,也增加了對 資料基礎設施(Data infrastructure)的投入,畢竟,要有高品質的資料流才能撐得起 AI 模型的訓練與推論。當公司內部資料流數量提升、資料類型也更加多變,勢必需要數據分析專才來讓這些資料除了作為供應模型的原料以外,能發揮更大商業影響力。
不只是開發 AI 產品的公司,使用 AI 產品的公司也將增加對資料科學專業的需求。No-Code AI 工具將加速資料科學的普及(democratizing),原本許多資源有限的公司,光是基本的資料串接以及數據報表呈現就忙得不可開交,No-Code AI 工具幫大家(即使完全不懂工程技術也能)高效率自動化、減輕做這些雜事的負擔之後,公司更有餘裕投入資源、研究怎麼從單純看看數字昇華成高價值資料應用。
第二,「人類」本身就是 AI 無法取代的特質,AI 再怎麼厲害,最終做出決策的終究是「人」,沒有公司會將商業問題全權交予 AI 或機器決斷。因此,我相信資料科學家的價值是成為人類決策者與先進數據工具之間的知識橋樑,即使 AI (或各種深度學習模型)擅長處理大量資料並識別模式,它們缺乏人類所具有的專業知識和經驗,無法將業務問題轉化為 可執行 的解決方案。
AI 無法做好與人類同等級的溝通,或者說,人類內心存在「期待有人性溫暖的溝通」這種偏誤,我們盼望人人都有的同理心就是一例。企業遇到諸如制定戰略和提升業務效率等等關鍵商業問題,仍需要資料科學家來深入理解團隊需求、並且解釋和應用數據來輔佐決策。
第三,人類資料科學家的優勢是創新能力,AI 模型的本質是以極高效率 回顧歷史,具有前瞻性的全新玩意還是要由人類來發想,資料科學領域亦然。舉例而言,各界都在開發生成式 AI 產品的同時,「如何評估生成式 AI 的成效」就是一個新穎、且需求不斷竄升的研究議題。LinkedIn 開發 GenAI 產品時,資料科學團隊嘗試 整合質化與量化 的新方法來評估產品帶給使用者的體驗究竟是好是壞,人類資料科學家結合過往經驗與當下的情境脈絡,才能做到這樣的創新,這是 AI (還)無法取代的能力。

(來源:Daliana’s LinkedIn)
最後一點是道德和社會規範。模型只會追求最佳化、不在乎如何取得與生成資料,生成式 AI 甚至有可能產生有害或誤導性的內容,資料科學家和數據分析師能夠確保以道德與合規的方式運用資料。歐盟的《數位市場法案》(DMA)就是一個為了避免科技巨頭壟斷、而限制使用者資料取用的案例,壟斷本身是主觀的概念,AI 模型無法做出與人類主觀意識一致的判斷、來決定取用哪些資料符合規定。想讓資料被最佳運用、又要保證使用者資料取用符合 DMA 規範,非得要人類數據專家介入才能做出權衡。
如果你閱讀到這裡,很謝謝你參考我的觀點,我仍必須打預防針:長期的就業市場變化趨勢沒人能預測。我的觀點說不定很短視、沒看見 AI 長期可能吞噬資料科學工作的可能性,但至少以上四點是我撰文的現在(2024 年年中)深信資料科學家依然會在業界被需要的理由。這四點論述以質化分析為主,若你更偏好量化數據預測,這個 Kaggle 公開資料 蒐集了數據分析師職位數量變化,而且持續更新中,值得你拿來研究當下的就業市場趨勢。
Data 職能的需求還會存在,然而,資料科學是不是值得投入的職涯,取決於你有多少隨著時代進步的韌性,下個小節將詳述這點。
資料科學家的技能會被 AI 取代嗎?#
要探討資料科學家的技能是否會被人工智慧取代,我想先換個問法:哪些資料科學技能是 AI 飛速成長的現在、還被就業市場需要的?
我們可以細看孕育出 ChatGPT 的 OpenAI 所貼出的徵才訊息,來找出端倪。以下,我們簡單介紹 OpenAI 對 Data Scientist 要求的其中四項能力:
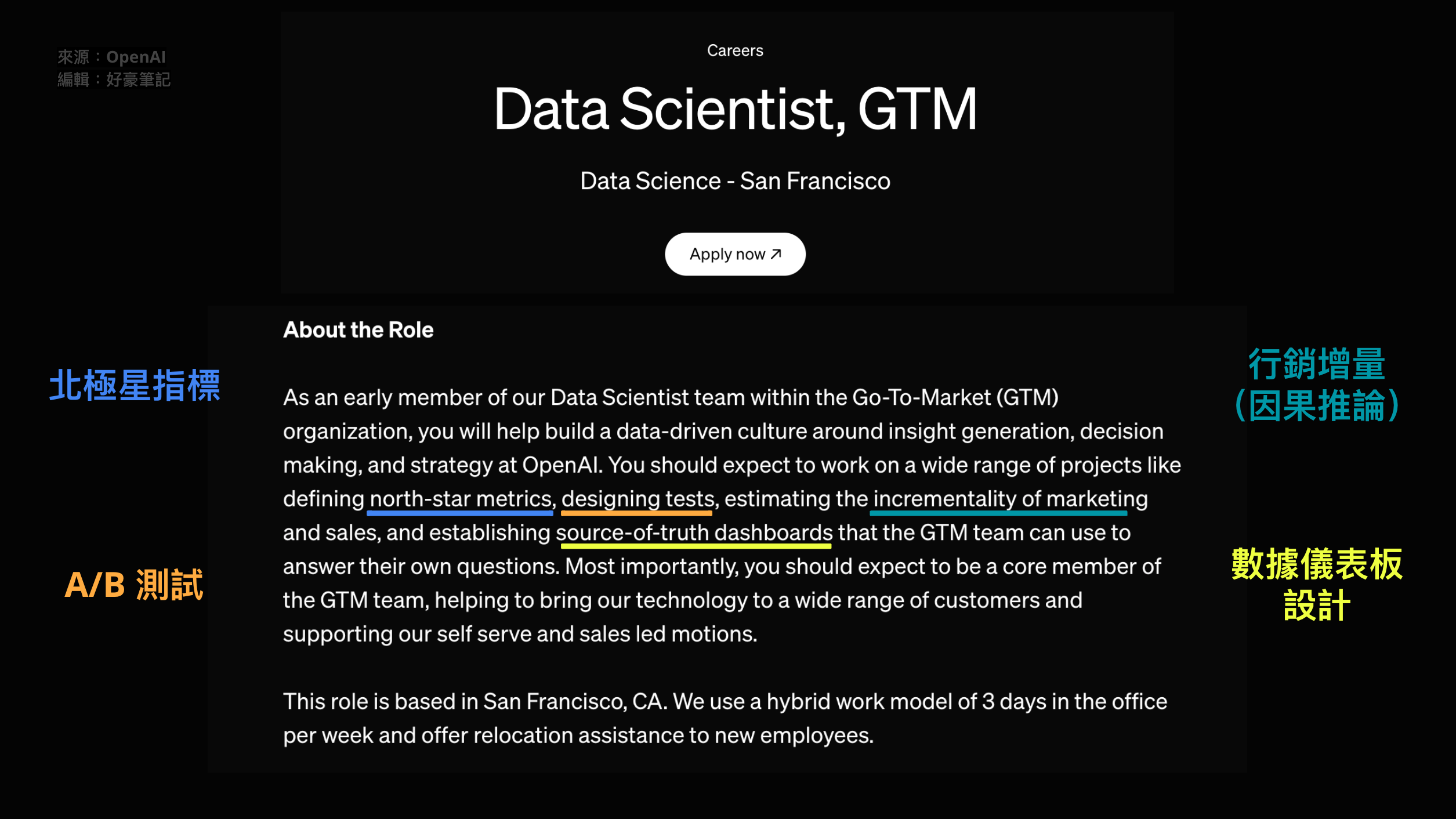
(圖片來源:OpenAI 公司網站,截圖於 2024 年 7 月)
北極星指標開發#
任何產品與服務都仰賴指標來監控其成效,成功指標可以是關鍵績效指標(KPI),像是營收或留存,若追求可引導行動方案的領先指標,我們會開發 北極星指標(North Star Metric)。
北極星指標是反映產品價值與商業戰略、並與未來營收高度相關的成功指標,如其名,它能夠指引整個團隊產品開發的共同方向,是與 KPI 相輔相成的存在。或許 AI 能夠快速梳理大量資料、辨識出多項潛在指標,只有資料科學家才能將企業的背景脈絡納入分析、把指標化為洞見與可執行方案。簡單地舉例,每月活躍用戶(MAU)是不是一個好的北極星指標?想回答這個問題得要深入理解產品的商業目標、生命週期、以及市場特性,並由資料科學家發揮溝通能力,在團隊成員與決策者之間穿針引線,才能讓成功指標真正成為全團隊齊心追尋的北極星。
(業界案例參考:LinkedIn 開發北極星指標遇到的實務困境、與其解決方案)
A/B 測試#
究竟產品有沒有「因為」你的努力改進而更討喜?
A/B 測試是鐵證
A/B 測試 是因果推論的聖盃(golden standard),透過隨機對照試驗(RCT),我們不需被太多假設限制、也能證明有因果關係的結論。
開發 GenAI 模型的科技公司 OpenAI 理所當然也需要 A/B 測試。ChatGPT 回答的語氣應該要更輕鬆還是更嚴肅?AI 該不該主動向使用者提問尋求更多資訊?這些產品的改進想法來自 AI 設計者,但這些改進是否真的有用不是產品經理一人獨斷,唯有使用者表現出喜歡才算數,而使用者的喜好仰賴商業實驗來橫量。
AI 工具確實可以自動化許多 A/B 測試流程,像是 VWO 可以透過 AI 幫你調整網站樣式並且自動進行實驗,然而,A/B Test 該怎麼設計實驗,要由決策者與數據分析專家協作討論來決定:
- 實驗該選用什麼指標來才能影響行動方針?又該怎麼選護欄指標(Guardrail Metric)來保障使用者體驗?
- 隨機對照試驗以「人」為隨機單位可行嗎?還是該以時間或地點作為隨機單位?
- 若實驗者會彼此影響(interference),以人為隨機單位是不可行的
- 後者做法稱為 Switchback Test
- 怎麼決定 A/B Test 的 樣本數 以及執行多久?能不能在產品更新出現意外的時候,提早結束實驗以 避免使用者氣瘋?
- 該選擇哪些使用者實驗?現有使用者的「好奇心效應」(Novelty Effect)怎麼解決?
A/B 測試是結合統計與工程知識的廣大研究領域,資料科學家將活用數理統計、因果推論、加上實驗設計的專業知識,讓 A/B Test 能真正實踐數據驅動決策、並且避免不夠周詳的實驗造成有偏誤的數據解讀,上述議題甚至不見得存在標準答案、更要結合現實情況選擇權衡,這些重大任務可不是 AI 能夠做到的。
因果推論#
OpenAI 的資料科學家職責,其中一項重要關鍵字是「incrementality of marketing」,行銷領域的 incrementality 指的是特定行銷活動對於企業成功指標的獨立效果,這在資料科學的行話正是因果推論(Causal Inference)問題。
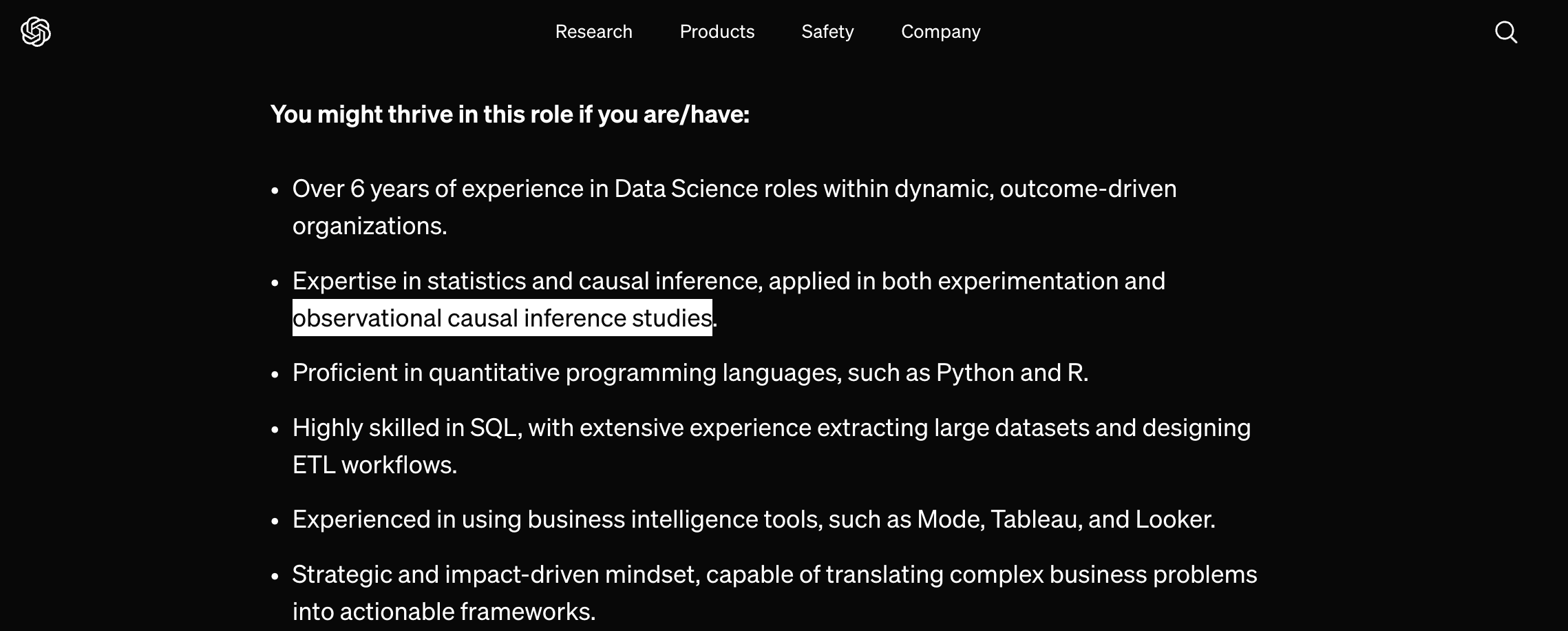
(圖片來源:OpenAI 公司網站,截圖於 2024 年 7 月)
在上個小節我們剛聊過,想知道行銷活動有沒有對產品成長更有幫助,A/B 測試能夠作為鐵證,但是,有太多情境不適合採用隨機對照實驗。假設你是類似蝦皮的電商平台,想知道在雙十一活動開始前進行廣告活動是否能夠提升營業額,想像你把全部用戶依照「是否收到廣告」分成兩半進行 A/B 測試後,發現收到廣告使得用戶雙十一消費率提升 10%,也表示另一半用戶沒收到行銷廣告、沒提升消費率,有 5% 的總營收是少賺的,你能接受嗎?
即使情境不適合做實驗,我們也依然想從過去已發生的種種產品改進或行銷活動中,衡量每個決策「造成」多大影響。當我們手上只有未經過商業實驗設計的一般歷史資料,此類分析稱為觀察性研究(Observational study),想透過觀察性研究解析出因果關係十分不易,經典的難題包括混淆變項與自我選擇偏誤等等,這個排除萬難以推論因果關係的研究過程正是上方 OpenAI 職缺圖示提到的 Observational Causal Inference Studies。
AI 只擅長加速資料處理與機械化的機器學習模型運算,活用因果推論的思考框架則是現代資料科學家的核心競爭力:為模糊的情境建模、驗證各種因果推論的假設,最後精確衡量出每個決策的獨立效果。
(延伸閱讀:因果推論如何衡量「平行世界」?混淆變項與自我選擇偏誤又是什麼?)
數據儀表板產品設計#
以現在資料科學家的能力要求,「做出」數據儀表板的 SQL、Tableau、PowerBI、或者 Looker 的技術知識只是最基本,因為 AI 已經可以讓非工程背景的使用者,也能 快速進行資料視覺化、甚至達成進階的預測分析。
相信筆者已提過無數次了,做出儀表板看看數字只是最粗淺的層次,真正有價值的是如何應用數據、影響決策。資料科學家更該像是數據儀表板這項產品的產品經理,做出產品只是一回事、進一步要在乎產品有沒有被團隊成員認為有用。OpenAI 的職位要求以「socialize dashboards」來描述這項能力,字面意義是讓數據儀表板普及化,實際上是期待資料科學家理解團隊需求、監控資料品質、並主動提煉資料洞察,確保數據儀表板這項產品是被所有人信任且樂於使用的。企業徵求的是以數據儀表板為媒介、能夠驅動決策的領導者,而不是只忙於把儀表板變漂亮的撈數據工具人。用一句話總結:資料科學家高度要求 領導特質與溝通能力。
寫到這裡,我們試著相信 Data 職能需求會持續存在、專業分析能力也不會立即被 AI 取代,那麼下個問題是:現在投入資料科學家職涯,該用什麼方式努力?
想在資料科學領域發展,我們該做什麼?#
我相信 Data 工作不會消失,初階(junior level)的資料科學家職位也不會消失
它們只是會不斷被重新定義
把昨天的 Senior 當作今天的 Junior#
現今的資料科學工作已經與過去非常不同,以前光是會用 Python 或 R 語言做到網頁爬蟲、統計分析、或者 資料視覺化,已經是足以讓資料科學家順利入行的技能,現在有了各種 AI 工具,這些任務光是用人類語氣輸入幾個字就能做到、完全不稀奇。
無可避免地,過去這些屬於基層數據分析的職位正在銳減,不只是數據分析,任何行業最初階、機械化、高重複性、單純勞務而少有創意的技能都會被 AI 取代。這不表示初階資料科學家的工作會全面消失,而是代表我們會用以往「資深」的標準來要求每一個數據分析師,入門資料科學家的門檻將被重新定義。
(截圖來源:daily.dev)
以前,企業必須特別徵求初階員工來處理基礎勞務,高層次的戰略思維交給資深員工;現在,AI 將處理所有基礎勞務,你想踏入公司掙個飯碗,就得擁有以往公司要求資深員工的高階能力。換言之,我們需要「跑在 AI 前面」,當 AI 取代了初階技能,我們就先一步往資深技能邁進。
就如上個小節的儀表板範例,以前你或許可以把「操作 Tableau」製作數據儀表板當作一項專長、放在履歷上,現在這一點也不稀罕,隨便搜尋就能找到用自然語言的提示詞、幾分鐘內做好超美數據儀表板的 AI 工具。
人際溝通、問題解決、以及決策影響能力,在過去聽起來比較像是對資深資料科學家的要求,現在則是從你人生第一場資料科學面試就得要展現出這些領導力。還想只把製作數據儀表板當作有競爭力的專長?這行不通了。撈數據、畫圖表這種「資料雜工」公司花點錢買 AI 產品來處理就好,何必要特意聘人來做呢?
我很喜歡 Stella & Amy 在 Podcast 提到的一個比喻:現代 AI 就像是給每個人無限多個實習生為你處理庶務、大幅降低認知負荷,讓我們脫離單純的勞工、而能夠成為自己職位的 CEO,把心力專注於真正對產品與團隊貢獻最高價值的戰略性思考。
(碎嘴一下,不確定什麼叫「更高層次」的資料科學實力嗎?當你開始獨立思考、批判類似「帶你 10 週就成為資料科學家」這種氾濫自媒體線上課程可行性的時候,已經是成功的第一步了)
想在這行生存,我們得有意識地磨練符合不會被 AI 取代的資深標準、又滿足就業市場需要的技能,但這些標準是什麼?不會有正解,只能保持警覺。筆者好豪自己的做法就如這篇文章所示,持續關注 OpenAI 這種大公司的徵才要求作為參考點,與自己擁有的技能比較、檢視自己的不足。我個人相信前述的北極星指標、A/B 測試、因果推論、數據說故事加上儀表板驅動決策能力等等,都是(產品分析)資料科學家必備技能,也認為未來想投入這行的新人,若還對這些面向一無所知,很難混得好。
在陸續認識很多同行後,我很殘忍地說,現在會發自內心害怕被 AI 取代的數據分析師,這類人即使能活在另一個 ChatGPT 沒被發明的平行世界,他們也一輩子達不到資深分析師的水準。
活用 AI,而不是怕被 AI 取代#
AI 不會取代人類,但懂得活用 AI 的人會取代不懂 AI 的人
哈佛商學院教授 Karim Lakhani
看完上個小節,你有沒有在心中吐槽:「明明還沒入行,怎麼可能學習資深資料科學家的能力」?覺得我的觀點鬼話連篇?
蘋果橘子經濟學曾在 Podcast 提出對新文明使所有人卓越的論點:莫札特無庸置疑是音樂天才,但與現今受過正統音樂教育的年輕學子相比,他的演奏並不算是突出,關鍵就在於教育方法與人類累積的知識隨著時間進步飛快。
這個論點也適用於現在:曾經你以為學習門檻很高的技能與知識,都可能經由 AI 的幫助,讓你快速成為專家。比起害怕被 AI 取代,我會更樂觀地解讀,AI 讓大多數人學習效率都高速成長、人人都能成為專家,我們能接觸到的知識量比三十年前只要精通 Excel 就能當分析師的前人們多太多了,這是種幸福。新工具能夠大幅提升你的專業能力水準,我們每個人都得承認這項事實與趨勢,並以 AI 重塑汲取知識的方式,強迫自己 超速學習。
舉例來說,我還記得我 2017 年左右剛入行的時候,第一次聽到 CUPED 這個較進階的 A/B 測試技巧,當時白話的教學文章不多,原始論文我第一眼也沒有全盤看懂、只學了皮毛,有點害臊地說,2024 年初我在 某次面試 被問到這項 CUPED 方法,我的回答實在稱不上紮實。
後來我發奮再次挑戰徹底讀懂該論文,好奇心使然之下,我先問了 LLM 要怎麼看懂 CUPED 論文,赫然發現 AI 回覆的解釋非常淺顯易懂!它可以用老嫗能解的方式介紹論文的核心概念,它幫助我看懂了全文梗概後,我接著閱讀論文每個細節與公式就變得容易許多。這個經驗讓我從此都積極使用 ChatGPT 或 NotebookLM 等工具來輔助我學習困難與複雜的知識,看著 AI 的精美摘要總是讓我想:要是以前讀論文就有 AI 幫助我,那該有多好!

要是面試官聽到這種深入淺出的回答,或許會讓 AI 錄取資深資料分析師!
(截圖來源:Google Gemini)
此外,如果你是已經在資料科學家打滾的業界人士,我想再次引用上個小節的比喻:你是否有讓 AI 發揮像是有無限多個實習生為你工作的威力?不懂得讓 AI 為自己所用,而只是害怕被 AI 取代,不就是坐以待斃的意思嗎?我曾經也是懷疑 AI 只是泡沫的吃瓜群眾,是在職場親眼看過許多人透過 AI 提升工作效率後,才重整心情,把自己當作 AI 文盲 從零開始學習用 ChatGPT 與 Gemini 提升生產力。
擁抱「不確定」的資料科學趨勢#
資料科學自始自終是一個充滿不確定的職涯領域。職能的定義十分多樣化,資料科學家沒有標準定義,商業分析、資料工程、機器學習、或 MLOps 等等都算是資料科學家;流行的方法與技能也是日新月異,可以看看資料社群 PyData 每年火紅的議題都有多大的差別,又或者回想幾年前 R 語言曾是熱門統計分析程式語言、而現在變成 Python 主導話語權。
因此,想在這一行深耕,資料科學家最重要的能力是終身學習。
不存在任何程式語言或技能,可以永遠保障你的資料科學家飯碗。關注大公司的技術發展、與同行保持交流、查看新職缺需求變化等等,積極與主動了解資料科學領域的變化是在此生存的基本功。我個人的具體作法是閱讀 科技公司部落格 分享的實戰案例,掌握不同產業面臨的新挑戰以及如何用資料解決,當作一種「不出門而能知天下事」的方式。
我記得多年前,某場公司面試的最後一關,總監等級的面試官問了一堆跟我個性有關的行為面試題(behavioral question)、完全沒跟我聊資料分析,我最後忍不住問他:不用問問我的分析專業能力嗎?而他斬釘截鐵地告訴我,他會花時間了解我的個性,因為他想知道面試者是否能夠「在不確定的環境下生存」,這是他多年分析經驗總結出最關鍵、也是他最看重的能力。我也是隨著工作經驗逐漸累積,才越來越體認到這一點。
要是你追求確定、穩定,或是對資料科學的熱愛不足以支持你天天追求新知,那我會建議你:
考慮一下資料科學家以外的職涯吧 (˚∀˚)
結語:說了一堆,其實就業市場才是關鍵#
目標要是放在找一份資料科學工作,毫不諱言,比起以上說了一堆,其實經濟情勢與就業市場決定一切啦!經濟火熱的時候,每家公司都用 FOMO 的心態搶人,這種時候,只要你的履歷稍微寫點大數據關鍵字,還真能找到位子餬口。
然而沒有天天過年的、景氣不是年年都好,筆者撰文的 2024 年正是就業市場萎縮、資料科學職位也在隨著 AI 轉型的一年,因此越來越多人在問還能不能找到資料科學工作、害怕數據分析全被 AI 取代。
我們對 AI 要保持謙遜學習的心,並不用過度害怕 AI 取代自己,AI 再強、也比不上我們對企業運作的理解、與人溝通的同理心、或是跨越新挑戰的創新能力,這些特質將使人類資料科學家持續被業界需要。
未來想在資料科學長期發展,該擺脫學個幾週 Python、PowerBI、SQL 就自以為能當數據分析師的迷思了,我們需要加速自己提升專業能力的層次、以 AI 為我們的學習效率賦能、然後不斷關注新趨勢,才能讓自己超越 AI、跟得上時代。
看到這裡,如果你有熱情想找到資料科學工作,在此推薦你參考我以前的職涯心得文章:
要是你讀了文章還有其他職涯問題,請透過 Google 表單 給我意見回饋,或者 聯絡我 討論職涯諮詢的方式,我很有興趣聽聽你對資料科學職業發展的想法。
最後,歡迎你利用以下按鈕,將本文加入書籤或者分享出去!並推薦你追蹤 好豪的 Facebook 粉絲專頁 以及 Threads 帳號,我會持續和你分享在資料科學業界工作的心得與相關知識。