
A/B Test 要多少樣本數才夠?
到底實驗要做多久才可以?
這是做 A/B Test 的產品設計者、行銷專家、還有資料科學家們永遠都在問的萬年問題,我認為,大家一直在問同樣這個問題,主要理由有二:不熟悉統計學、不懂公式的來由;以及沒有數據「直覺」,一被人質問延伸問題就被問倒了。這則筆記將為你解決這兩個痛點,不只說明樣本數怎麼算、背後的數學公式與假設、用 Python 如何計算,也將介紹「為什麼」這樣算的統計直覺,讓你不再害怕被其他人問「到底為什麼樣本數要這樣算?」。
另外,如果你在網路上用英文關鍵字搜尋過「Sample Size」,很可能看過 Evan Miller 設計的熱門 A/B Test 樣本數計算機,網頁中他提到自己是用 \(n = 16 \frac{\sigma^2}{\delta^2}\) 這個公式,此公式簡短到令人懷疑這個黑盒子內究竟算了什麼,網站也無法一眼看出用到了哪些假設,本文將會一一拆解 Evan Miller 的計算方法,並用 Python 程式碼秀給你看,讓你未來要估算樣本數時,不見得要依賴網路搜尋,可以自己用 Python 算出來。
本篇筆記的 Python 程式碼,都分享在筆者 Github 裡,你可以用 Google Colab 開啟,立刻自己實做看看。

(圖片來源:Evan Miller)
為什麼要計較 A/B Test 的樣本數?#
我們先稍微聊聊究竟資料分析為什麼要這麼在意 A/B Test 的樣本數有多少。難道,不是只要做好隨機對照實驗(RCT)、在假設檢定看到顯著就能馬上下結論嗎?沒這麼簡單!
當 A/B Test 樣本數過少時,統計檢定力往往會不足,也就是,即使你的產品新設計確實對使用者有幫助,商業實驗也看不出顯著性。更麻煩的問題是,如果產品每天能蒐集的樣本很少,我們常會急切地天天盯著 A/B Test 結果看,如果看到資料反映出統計檢定顯著,馬上下結論、結束實驗,這種在樣本數不足下「偷看」的動作會造成持續監控問題,其中的抽樣偏誤會使得實驗的統計錯誤大大提高!對此「偷看」問題更詳盡的說明我寫在 這篇筆記 供你參考。
而當 A/B Test 樣本數過多也不全然是好事情,不是資料越多就一定越好。首先,對某些使用者流量還不太高的產品而言,每個樣本都超珍貴、多蒐集幾個樣本可能要花不少時間。如果你蒐集了比你實際上需要還多很多的樣本,就會多浪費好幾天蒐集樣本、還對實驗沒什麼貢獻。而且別忘了,A/B Test 會讓你的使用者看到跟平常不一樣的產品,這個不一樣或許是暫時的、未來或許會變回原狀(因為你的實驗有可能告訴你使用者其實不青睞新設計),因此我們當然希望因為 A/B Test 而看到這個「不一樣」的使用者樣本越少越好,我們不會想讓太多人看到我們反反覆覆修改著產品設計的過程。
此外,當樣本數超級大的時候,通常 P 值(P-value)都會很小,換言之,只要你的樣本數超多,幾乎都能看到統計顯著、拒絕虛無假設,但樣本數過多的統計顯著往往只伴隨著很小很小的效果,會是「不實用」的統計顯著(Statistically significant, but not practically significant)。舉例而言,假設有藥廠發明了一種藥,可以讓身高增加 0.2 公分,他們找了超大一群樣本、也真的在實驗看出統計顯著性,但你會為了想長高 0.2 公分冒險吃這種藥嗎?這就是統計顯著不太「實用」(Practical Significance)的意思。如果你還想知道樣本數過大還會造成哪些其他 P-value 問題,推薦你找時間細細品嚐這篇 Too big to fail 論文。
總之,想要為產品高效率執行 A/B Test,我們要找個剛剛好的樣本數,不能太低、也不能太多。我們接著談談,究竟是哪些要素影響你需要樣本數的多寡?
決定所需樣本數的四大要素#
在亮出數學公式以前,我們先來討論到底 A/B Test 的樣本數會被哪些要素影響,是什麼會讓需要的樣本數更多或更少。以下將會提及四大要素:樣本標準差、Minimum Detectable Effect、還有型一與型二錯誤。
樣本標準差#
樣本標準差越大、A/B Test 需要的樣本數越多
樣本標準差(Standard Deviation)衡量樣本內數值的離散程度,樣本內的數值如果很發散,我們會更難結論兩組數據間的差異。直接舉個例子來想像,假設已經知道A地區的平均身高是 165 公分:
- 如果你在B地區抽樣出 5 個人:158、163、170、172、177 公分
- 即使樣本平均是 168 公分,但是數據很發散(樣本標準差很大)
- 讓你不敢斷言「B地區平均身高高於A地區」,或許還需要 30 個樣本以上才能下結論
- 如果你在C地區抽樣出 5 個人:166、166、167、168、169 公分
- 雖然平均數只比A地區高 2 公分,但是每筆數據都很接近 167 公分、資料相當集中(樣本標準差很小)
- 你可能會在心中想著:只要再抽樣 3 個人、他們身高也同樣接近 167 公分的話,你或許已經願意相信「B地區平均身高高於A地區」
樣本標準差的影響亦可以用鐘型曲線來視覺化。統計學常會對估計值畫出鐘型曲線來呈現其分佈,A/B Test 兩組的樣本平均數分佈可以各自畫出鐘型曲線,很概略地說,(見下圖)兩個鐘型曲線只要重疊的部分很少、就會有統計顯著。所以,樣本標準差對決定樣本數的影響可以這樣思考:
- 鐘型曲線越「瘦高」,越不容易重疊(越容易統計顯著)
- A/B Test 樣本數越多,標準誤會越小、鐘型曲線會越瘦高
- 而當樣本標準差越小,標準誤也會越小
- 那就表示樣本標準差很小的時候,樣本數可以不用那麼多,鐘型曲線也能保持同樣瘦高、同樣容易呈現統計顯著
- 「容易呈現統計顯著」的程度就是統計學家口中的 檢定力(Statistical Power)
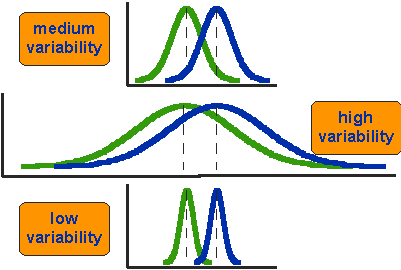
而樣本標準差越小會使鐘型曲線越「瘦高」、越不容易重疊
(圖片來源:Prof William M.K. Trochim)
如果你還不清楚標準差跟標準誤的區別、或者不太了解為什麼標準差跟鐘型曲線的高矮胖瘦有關係,強烈建議你繼續閱讀筆者好豪之前寫過的筆記:深度理解標準誤與標準差。
Minimum Detectable Effect (MDE)#
MDE 越大、A/B Test 需要的樣本數越少
Minimum Detectable Effect(MDE)是期望最小的指標效果差異,它是主觀設定的,它可能取自於你的產品設計理念,例如幫 APP 某個按鈕換造型預計提升 10% 點擊率;也可能來自於商業策略問題,例如這個 APP 按鈕的點擊率如果無法成長 10%,那將會不符成本、不值得改變產品。
決定樣本數的時候就把 MDE 考慮進去,將會解決剛剛提到的「不實用」統計顯著問題,因為你事先設定好你的數據至少要看到多大差異才算是實用,只要你使用剛剛好的樣本數來做商業實驗,最後如果看到實驗呈現出統計顯著,其效果肯定不小於 MDE、必然是「實用」的統計顯著(Practical Significance)。
筆者好豪在此囉唆提醒,MDE 是在 A/B Test 開始之前就(主觀)決定好的,MDE 不是指實際實驗數據的兩組平均數差異(因為實驗還沒開始做、不知道實際差異)。
當你設定的 MDE 越小,實驗需要的樣本數越高;反之,MDE 越大,需要樣本數越少。就用上個小節的「長高藥」來舉例吧,假設已知控制組的平均身高是 165 公分:
- 如果實驗者設定 MDE 為 1 公分,你陸續蒐集了幾個樣本分別是 166 公分、164 公分、172 公分
- 實驗組平均雖然比控制組高了 2 公分,你可能還是會心想:「不能結論長高藥有效!或許有抽樣偏誤存在,是運氣好抽到一位特別高的樣本才有這種結果」
- 還要多蒐集很多樣本才敢結論到底有沒有長高效果
- 如果實驗者設定 MDE 為 20 公分,而你目前蒐集到幾個樣本分別是 187 公分、174 公分、189 公分
- 實驗組平均只比控制組高了 18 公分、不到 MDE 設定的 20 公分
- 但光是實驗組蒐集這少少 3 個樣本相對於控制組都有很大的效果,你是否也開始相信這個長高藥好像真的有效了?
此外,MDE 對樣本數的影響也同樣可以用鐘型曲線來想像。
- A/B Test 樣本數越多,標準誤會越小、鐘型曲線會越瘦高
- 而 MDE 越大,對照組的鐘型曲線會越往右邊平移、與另個鐘型曲線的重疊會越少
- 換言之,MDE 越大,樣本數即使少一點、鐘型曲線矮胖一點,也同樣容易出現統計顯著
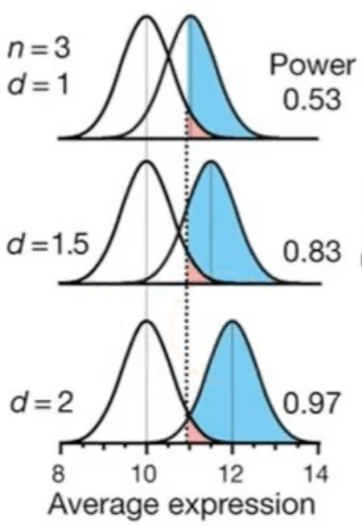
(圖片來源:Courtney Donovan)
型一與型二錯誤#
允許的型一與型二錯誤率越高、A/B Test 需要的樣本數越少
統計方法不是完美的,不管你進行假設檢定之後看到顯著或不顯著,都還是有機會讓你造成錯誤結論。有可能抽樣時恰好運氣不佳,使得你抽到的樣本對於母體不具有代表性、無法反映出母體的真實特徵,這種出現 抽樣偏誤 的隨機性會使我們錯誤推論資料。統計學家將這種 A/B Test 「預期會發生」的錯誤分成兩種:
- 型一錯誤(
α或 Type I Error):A/B 兩組其實並沒有差異,統計檢定卻因為隨機性判定成有差異(偽陽性錯誤) - 型二錯誤(
β或 Type II Error):A/B 兩組確實有差異,統計檢定卻沒有偵測到顯著(偽陰性錯誤)
(如果文字敘述太抽象,推薦你閱讀 這篇文章的圖片案例,幫助你直覺好懂地學習型一與型二錯誤)
如同人做的決策不可能完美無缺,統計檢定的型一與型二錯誤也不可能完全消除、但可以被控制,分析者可以自己決定容許統計方法有多少型一與型二錯誤存在。在資料越多時,你對估計值的衡量就越精確,(通常)也表示會產生的決策錯誤越少;反過來說,如果你允許發生的型一與型二錯誤越少,需要的樣本數就會越多。
在此,筆者好豪又要囉唆地註記,很多資料科學家會用 檢定力(Statistical Power)來描述型二錯誤,檢定力其實就只是 1-β、與原本的型二錯誤 β 一體兩面,只需要注意樣本數計算的統計直覺會變成:如果分析者要求 A/B Test 的檢定力(1-β)越高、需要的樣本數也會越多。
相對於剛剛討論的另外兩個因素(樣本標準差由資料決定、MDE 由產品設計者決定),一般來說,我們執行 A/B Test 會選擇的型一與型二錯誤率幾乎都是按照統計學的慣例、不太會更動:
- 型一錯誤設定為
α = 0.05α也被稱為顯著水準(Significance Level)- 這也是為什麼我們常常看到 95% 信賴區間
- (延伸閱讀:我該把顯著水準從 0.05 改成 0.01 嗎?)
- 型二錯誤設定為
β = 0.2- 也就是
檢定力 = 1-β = 80%
- 也就是
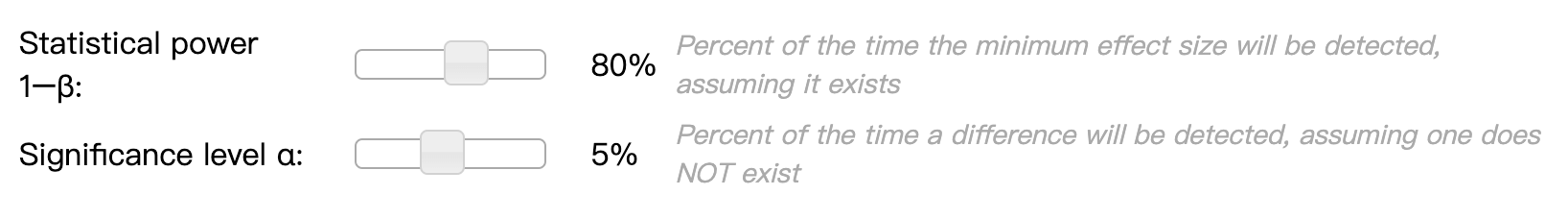
為什麼要你調整
α 與 1-β 了吧!(圖片來源:Evan Miller)
A/B Test 樣本數計算方法#
看完了會影響樣本數的四大要素,現在我們可以更從容的面對數學公式了!進行 A/B Test 的正確做法是預先決定實驗樣本數、並且禁止在蒐集到這個樣本數之前 偷看。那麼實驗樣本數究竟是怎麼算出來的呢?以下是計算方法的完整公式:
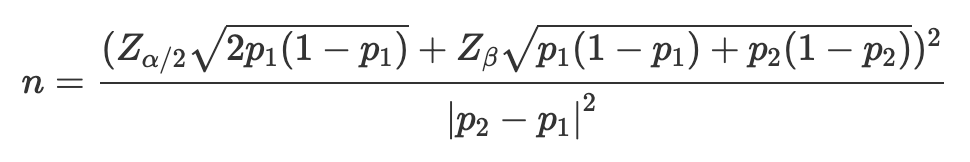
p1與p2分別是控制組與對照組的比例資料(例如 APP 的某個按鈕點擊率)- 此公式計算的是比例資料(
p),而連續型資料(例如身高)可同理計算,本文後面會補充
- 此公式計算的是比例資料(
p2是用p1 + MDE算出來的- \(\sqrt{p_1 (1-p_1)}\) 與 \(\sqrt{p_2 (1-p_2)}\) 指的就是樣本標準差
方才我們花了不少篇幅談了樣本數的四大要素,而上方這個看起來有點複雜的公式,實際上做的事情就是在你給定了四大要素之後,算出「為了符合這四大要素需要多少樣本數」。詳細的公式推導過程可以參考 這個網頁,我們在此先搞清楚這個公式在算什麼就好:此公式假設實驗的 A 與 B 兩組樣本數大小相同,換句話說,公式算出來的 n 是 A 與 B 其中一組的樣本數至少要是多少(注意 n 不是 A 與 B 的樣本數總和)。
計算這個樣本數公式需要的所有要素,正是我們上個小節提到的那四大要素,只要在公式代入這四大要素,就能算出樣本數囉。只是,看到這裡的你或許會疑惑,怎麼跟文章開頭提到的 \(n = 16 \frac{\sigma^2}{\delta^2}\) 公式不一樣,那個公式明明看起來簡單多了?
只要加入更多假設,上方那個有點複雜的公式是可以簡化、變得更實用的!
首先,上個小節在型一與型二錯誤段落有提到,我們通常會依照慣例設定 α = 0.05 與 β = 0.2,依此設定,可以用 Z 分數的標準常態分配表 來查表找出以下兩個公式內用到的數值:
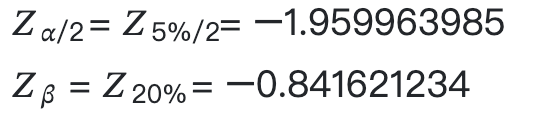
這些 Z 分數也可以用 Python 程式查出來:
from scipy import stats
alpha = 0.05
beta = 0.2
print(stats.norm.ppf(alpha/2)) # -1.9599639845400545
print(stats.norm.ppf(beta)) # -0.8416212335729142
另外,我們也通常會假設實驗的 A 與 B 兩組樣本變異數相同,也就是假設我們產品的新設計(A/B Test 的「干預」)雖然會有對平均數有效果、但是不會大幅影響資料的離散程度。按照此項假設,公式中的 p1 與 p2 各自的變異數,可以總結成單一個 合併變異數(Pooled Variance),讓公式內的 \(\sqrt{p_1(1-p_1)}\) 與 \(\sqrt{p_2(1-p_2)}\) 一起被替換成 \(\sqrt{pooled\ variance}\)。
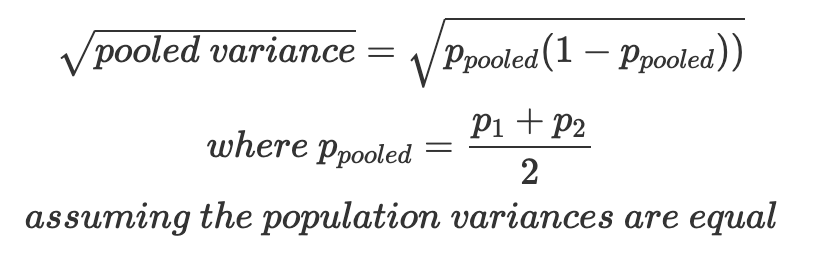
綜合以上加入的假設,原本介紹的樣本數計算公式就能簡化了:

- \(\delta\) (讀作 delta)就是四大要素中的 MDE
- \(\sqrt{variance}\) 只是簡化寫法,實際上 \(variance\) 是指合併變異數(Pooled Variance)
- 16 來自 \(3.96^2\) 的簡化
終於,我們得到 Evan Miller 提供的這個簡單好記的 A/B Test 樣本數計算公式了:

更棒的是,現在這個簡化後的公式不限於資料型態,不管你的 A/B Test 目標是連續型資料還是比例資料都能適用。我們可以用 Python 程式跑些模擬來驗證我們算出來樣本數的正確性,我直接幫你算出下方表格了,表格計算方法請到筆者好豪的 Python Notebook 查看囉。
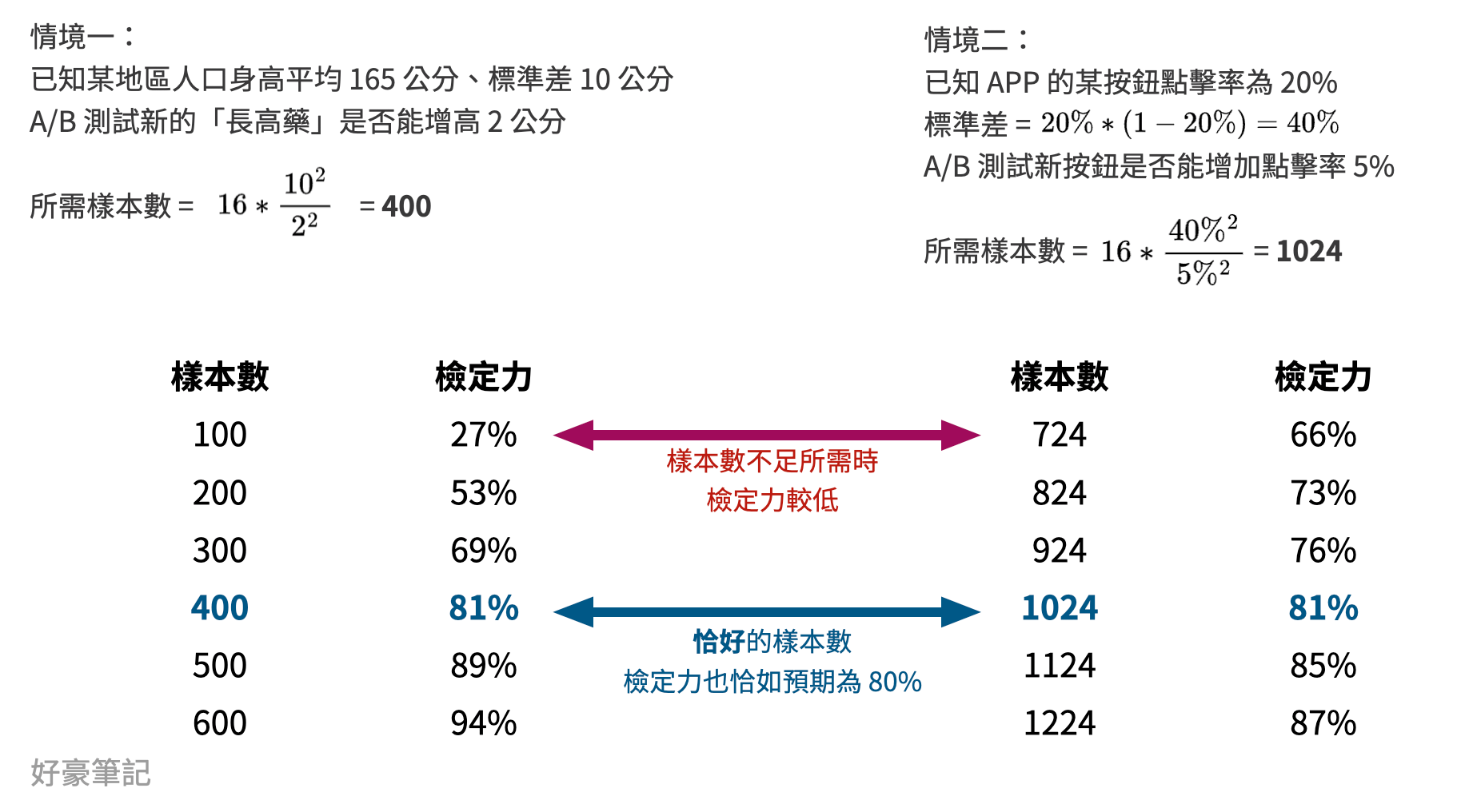
(製圖:好豪)
用 Python 計算 A/B Test 樣本數#
(接下來的 Python 範例,我們都將以 Evan Miller 網站預設參數:控制組比例 20% 且 MDE 為 5% 當作範例,看看 Python 能否算出接近本文開頭截圖的 1,030 樣本數)
簡化後的樣本數公式,只要你稍微用過 numpy 套件,寫出來這個公式不會太難:
import numpy as np
delta = 0.05
sigma = np.sqrt(0.2 * (1-0.2))
n = 16 * sigma**2 / delta ** 2
n
# 1024.0
除了直接寫簡化後的樣本數公式,筆者好豪在此想額外介紹,不用自己寫公式、而是用 Python 的 scipy 套件還有 statsmodels API 既成的函式該如何算出 A/B Test 樣本數:
import statsmodels.api as sm
sm.stats.samplesize_proportions_2indep_onetail(
diff = 0.05,
prop2 = 0.2,
power = 0.8,
alpha=0.05
)
# 1093.739
diff是 MDEprop2對應的是上方數學公式的p2,也就是「對照組」的比例資料- 同樣地,控制組與對照組是
p2 = p1 + MDE的對應關係
- 同樣地,控制組與對照組是
- 與上方數學公式相同,此函式預設 A 與 B 兩組樣本數大小相同
- 如果不同,需要調整函式內的
ratio參數
- 如果不同,需要調整函式內的
將函式對比上面討論的四大要素,你或許會問:樣本標準差怎麼不在參數裡呢?這依然是有考慮進去的!只是 samplesize_proportions_2indep_onetail() 函式專門計算比例資料的檢定所需樣本數,而比例資料的樣本標準差可以透過 \(\sigma = \sqrt{p*(1-p)}\) 算出來,函式會在背後幫你計算好、不需要我們自己輸入。
以上 Python 範例會計算出所需樣本數為 1,094,這跟本文最前面截圖的 Evan Miller 計算機範例(該網站點進去立刻會看到的預設值)是一模一樣的輸入,但 Evan Miller 算出來的樣本數是 1,030,為何會有些微的差異呢?經過筆者好豪研究後,雖然 samplesize_proportions_2indep_onetail() 函式跟 Evan Miller 計算機都假設 A 與 B 兩組變異數(或標準差)一樣,但是兩者計算時,取變異數的基準卻不同,統計學標準做法應該如 samplesize_proportions_2indep_onetail() 函式所為、使用 合併變異數(Pooled Variance);而 Evan Miller 在他的計算機則是直接取用控制組的變異數來算樣本數,不同變異數取用法造成兩種方法微小的樣本數差異,實務上,這個差異小到可以忽略,我認為兩種做法可以任意擇一施行。對此差異的詳情有興趣的話,請參考這則 StackExchange 問答。
公式的效果量形式(Cohen’s d)#
樣本數計算公式還可以用效果量的觀點來理解。
統計學課本所說的 效果量(Effect Size)是衡量兩個變數之間關係的強度,我自己則更喜歡把效果量想成考慮資料離散程度(變異數)後的效果大小相對值。舉例說明:
- 有兩個店家,在 Google Maps 上的平均評價分數(滿分 5 顆星)分別是 3 顆星跟 5 顆星
- 有兩個人,身高分別是 165 公分與 167 公分
這兩個例子中,雖然同樣都是兩個樣本差異的絕對數字為 2,但你仍會感覺前者的評價分數差很多、後者的身高則是差不多,這是因為它們的尺度單位不一樣、資料離散程度也不同。只要改為使用效果量就可以解決這項問題,效果量可以想成是為效果 標準化,以統一尺度來衡量效果。在 A/B Test 情境,效果量經常使用 Cohen’s d 來計算:
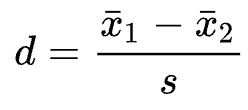
為什麼在這裡提效果量呢?仔細一看 Cohen’s d 的公式會發現,其分子正是我們前面討論過的 MDE(\(\delta\)),而分母是樣本標準差(\(\sigma\))。接下來我把 Cohen’s d 的效果量寫成 ES,再改寫一下樣本數計算公式:
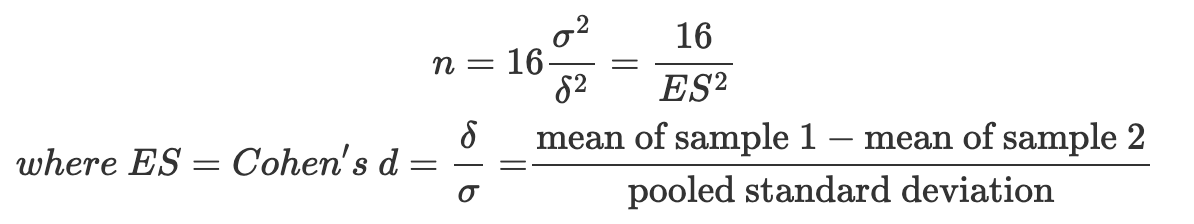
由此改寫後的公式來看,A/B Test 樣本數取決於標準化後的效果大小,換言之,樣本數是 Cohen’s d 的函數。
把樣本數轉換成 Cohen’s d 的函數來理解有多項好處,第一是幫我們建立「樣本數取決於效果大小」的統計直覺;其次,我們一開始引用的樣本計算公式適用於比例資料,而效果量用比例資料或連續型資料都能計算,也就是說,不論你的 A/B Test 目標是比例數據還是連續型數據,效果量轉換後的樣本計算公式都能適用。
最後,用 Cohen’s d 來看樣本數公式還能幫助我們理解 Python 程式碼!在網路上,你會查到 另一種 A/B Test 所需樣本數計算方法 如下:
import statsmodels.api as sm
es = sm.stats.proportion_effectsize(0.2, 0.25)
n = sm.stats.tt_ind_solve_power(
effect_size=es,
power=0.8,
alpha=0.05)
print(es) # -0.11990233319498567
print(n) # 1092.857352102658
tt_ind_solve_power() 的作用是找出「效果量、樣本數、α、β」這四個參數缺少的那一項,寫程式的時候你必須輸入其中三項,此函式會幫你算出你沒填入的那唯一一項。以上方函式來說,Effect Size(效果量)、α、還有 β(亦即 Power)都輸入了、只有樣本數沒有填入,所以函式最後幫你算出樣本數。
tt_ind_solve_power() 函式以 Effect Size 為輸入,概念就等同於剛剛說的「樣本數取決於效果大小」,這樣看來,這段程式碼是不是十分直觀呢?
對照上面介紹的 samplesize_proportions_2indep_onetail() 函式,在參數相同的前提下,算出來的所需樣本數確實是幾乎相同;你也可以再次對照本文最開頭的截圖,這段程式碼的確會算出與 Evan Miller 計算機 非常相近的結果。
(註:查看 原始碼 的話會發現 proportion_effectsize() 算的是 Cohen’s h 而不是 Cohen’s d,但實際上 d 與 h 的效果量數值大多情況下不會差很多,因此請原諒筆者在本文姑且混為一談)
結語#
恭喜你讀完這篇並不怎麼簡短的 A/B Test 教學筆記,希望看到最後的你,至少記得以下這幾個重點問題:
- 幹嘛管 A/B Test 的樣本數?樣本數太少會怎麼樣嗎?
- 實驗檢定力會不足、測不出有用的結果
- A/B Test 的樣本數不是越多越好嗎?太多又可能有什麼問題?
- 經常看見顯著、但是效果小到沒有幫助
- 多蒐集樣本在商業上也是一種成本
- 是什麼會影響 A/B Test 所需樣本數?
- 樣本標準差、Minimum Detectable Effect、還有型一與型二錯誤
- A/B Test 的樣本數怎麼算?
- \(n = 16 \frac{\sigma^2}{\delta^2}\)
A/B Test 是個看似簡單,實際上充滿統計學學問的領域,一個小動作做錯、就可能造成錯誤決策,別忽略了樣本數計算等等細節,才不會讓你的產品團隊精心準備的實驗都成為浪費時間。相信這則筆記,可以幫助你更理解這些 A/B Test 細節背後的邏輯。
這篇文章相關實驗的 Python 程式碼,都放在 我的 GitHub,分享給你親手玩玩看。
本文參考資料:
- Evan Miller: How Not To Run an A/B Test
- A/B Test 課本《Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing》(Amazon)
- 《資料科學的商業應用》
- 《資料科學家的實用統計學》
- Udemy 課程:貝氏統計與機器學習 A/B 測試
最後,如果你對 A/B Testing 有興趣,相信你會喜歡我的 A/B Testing 系列文章,推薦你繼續閱讀:
- A/A Test:商業實驗不能忘的前置動作
- 比例資料的 A/B Testing 該用卡方還是 Z 檢定?
- 多重檢定問題:一定會有人中樂透?!
- Novelty 與 Primacy Effect:好奇心殺死 A/B Test?
- A/B Testing 的單尾與雙尾檢定,該選哪一個?
如果這篇文章有幫助到你,歡迎追蹤好豪的 Facebook 粉絲專頁,我會持續分享資料科學以及 A/B Test 的實務操作心得;也可以點選下方按鈕,分享給熱愛數據分析的朋友們。